
NVIDIA’s latest GPU architectures, Blackwell and Hopper, are unequivocally at the vanguard of a profound AI revolution. Jensen Huang’s vision of data centers as “AI factories” is rapidly materializing, driven by these powerful accelerators that are fundamentally reshaping the computing landscape. We’re witnessing unprecedented performance leaps, with Blackwell delivering up to 30x faster inference and 4x faster training for trillion-parameter models compared to its predecessor, Hopper, all while achieving remarkable 25x greater performance per watt at ISO power. This monumental efficiency is powered by innovations such as the 208-billion-transistor Blackwell Superchip, the advanced NVFP4 precision for efficient LLM operations, the fifth-generation NVLink for massive GPU scaling, and the intelligent workload management of NVIDIA Dynamo. While these advancements promise a future of pervasive agentic and physical AI, with significant trickle-down benefits for areas like gaming (e.g., DLSS, frame generation), the community expresses understandable concerns regarding the increasing centralization of this technology and its accessibility for consumer-level applications. NVIDIA’s aggressive roadmap, extending to Blackwell Ultra and the Rubin platform, solidifies its commanding lead, yet the industry faces the critical challenge of ensuring this transformative power benefits the broader ecosystem.
The AI Factory Era: Reshaping the Computing Landscape
Jensen Huang’s pronouncement that data centers are evolving into “AI factories” isn’t hyperbole; it’s a precise articulation of a paradigm shift. NVIDIA’s Blackwell and Hopper GPUs are not merely components; they are the high-octane engines fueling this new industrial revolution. Traditional data centers, designed for retrieval-based computing, are giving way to highly specialized infrastructures singularly focused on the generation of “tokens”—the fundamental building blocks of AI. This transformation is driven by an unprecedented, exponential demand for compute power, largely spurred by the emergence of agentic AI and sophisticated reasoning models. As AI systems move beyond simple perception to complex reasoning, planning, and action, the computational overhead has, as Huang noted, increased by easily 100 times compared to just a year prior. This foundational role of GPUs in accelerating such workloads underscores their critical position in the ongoing evolution of computing, moving from general-purpose processing to highly specialized, accelerated intelligence.
Jensen Huang’s GTC keynote supercut visually reinforces the excitement and strategic vision behind NVIDIA’s ‘AI Factory’ announcements.
Blackwell Unleashed: Architecture for a New Age of AI
At the heart of NVIDIA’s AI factory vision lies the Blackwell architecture, a testament to groundbreaking engineering. This new class of AI Superchip boasts an astonishing 208 billion transistors, fabricated on a custom TSMC 4NP process. What truly sets Blackwell apart is its unified single GPU design, integrating two reticle-limited dies connected by an ultra-fast 10 terabytes per second (TB/s) chip-to-chip interconnect. This architectural marvel is purpose-built to accelerate the most demanding generative AI and advanced computing workloads. Key to its prowess is the second-generation Transformer Engine, which, combined with NVIDIA TensorRT-LLM and NeMo Framework innovations, dramatically boosts inference and training for large language models (LLMs) and Mixture-of-Experts (MoE) models. A significant innovation here is the introduction of NVFP4 precision, enabling highly efficient 4-bit floating-point AI that doubles performance and model size capacity while rigorously maintaining accuracy.

- Second-Generation Transformer Engine: Leveraging advanced Tensor Cores, this engine introduces new precisions, including the critical NVFP4 (4-bit floating point), which significantly optimizes performance and accuracy for LLM training and inference, enabling larger models with greater efficiency.
- Secure AI (Confidential Computing): Blackwell integrates hardware-based security with NVIDIA Confidential Computing, protecting sensitive data and AI models from unauthorized access. It’s the industry’s first TEE-I/O capable GPU, delivering nearly identical throughput performance even in encrypted modes.
- Fifth-Generation NVLink and NVLink Switch: Essential for exascale computing, this interconnect scales up to 576 GPUs, providing a staggering 130TB/s of GPU bandwidth within a 72-GPU NVLink domain (NVL72). The NVLink Switch Chip also enables 4x bandwidth efficiency with NVIDIA SHARP FP8 support, crucial for trillion-parameter models.
- Decompression Engine: Addressing the computational bottleneck in data analytics, Blackwell includes a dedicated Decompression Engine. This, coupled with high-speed links to the Grace CPU, accelerates database queries and data science workflows by supporting modern compression formats like LZ4, Snappy, and Deflate.
- RAS Engine (Reliability, Availability, Serviceability): To minimize downtime and enhance resilience in large-scale AI factories, Blackwell features an intelligent RAS Engine. It continuously monitors hardware and software health, identifies potential faults early, and provides in-depth diagnostics, significantly reducing operational costs and improving system uptime.
| Feature | GB200 NVL72 System | Single GB200 Superchip |
|---|---|---|
| FP4 Tensor Core Performance* | 1,440 PFLOPS | 40 PFLOPS |
| FP8 / FP8 Tensor Core Performance* | 720 PFLOPS | 20 PFLOPS |
| INT8 Tensor Core Performance* | 720 POPS | 20 POPS |
| FP16 / BF16 Tensor Core Performance* | 360 PFLOPS | 10 PFLOPS |
| TF32 Tensor Core Performance* | 180 PFLOPS | 5 PFLOPS |
| FP64 Tensor Core Performance | 3,240 TFLOPS | 90 TFLOPS |
| GPU Memory (HBM3e Capacity) | Up to 13.5 TB | Up to 384 GB |
| GPU Memory (HBM3e Bandwidth) | 576 TB/s | 16 TB/s |
| NVLink Bandwidth | 130 TB/s | 3.6 TB/s |
| CPU Cores (Arm Neoverse V2) | 2,952 Cores | 72 Cores |
| CPU Memory (LPDDR5X Capacity) | Up to 17 TB | Up to 480 GB |
| CPU Memory (LPDDR5X Bandwidth) | Up to 18.4 TB/s | Up to 18.4 TB/s |
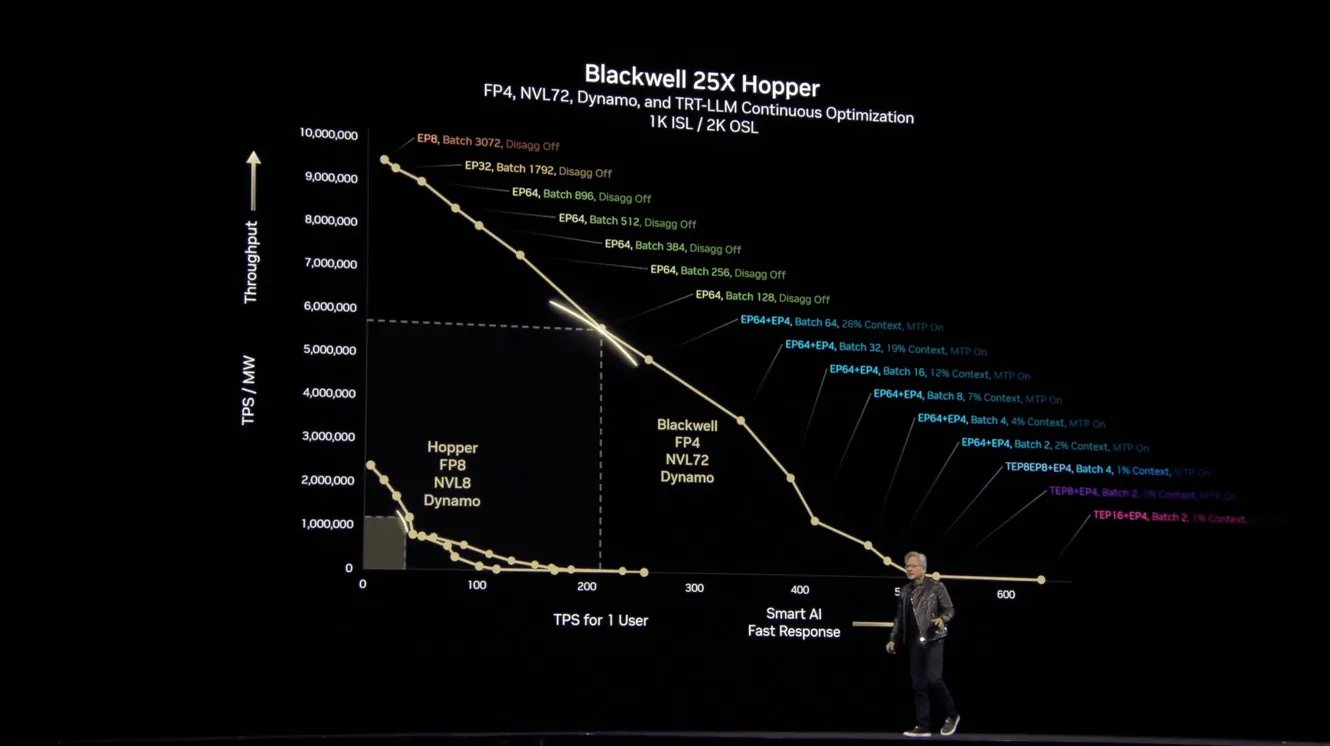
The Performance Crown: Blackwell vs. Hopper
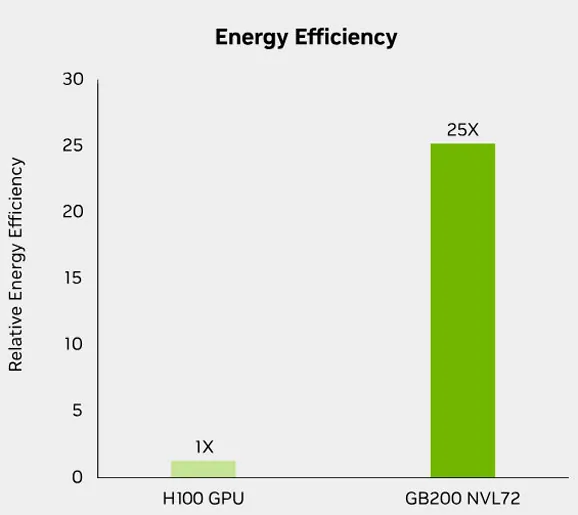
The generational leap from Hopper to Blackwell is nothing short of astounding, particularly for AI workloads. NVIDIA claims a staggering “40 times” performance increase for reasoning models with Blackwell compared to Hopper, a figure that dramatically reshapes the landscape of AI inference. Critically, the GB200 NVL72 system delivers “25x more performance at the same power” (ISO power) when stacked against H100 air-cooled infrastructure. This isn’t just a marginal improvement; it’s a fundamental re-evaluation of data center economics. For large language models (LLMs) with trillion parameters, these advancements translate to up to 30x faster real-time inference and approximately 4x faster training. Such gains directly lead to substantially reduced Total Cost of Ownership (TCO) and significantly lower energy consumption, making the deployment of increasingly complex AI models economically viable at scale.
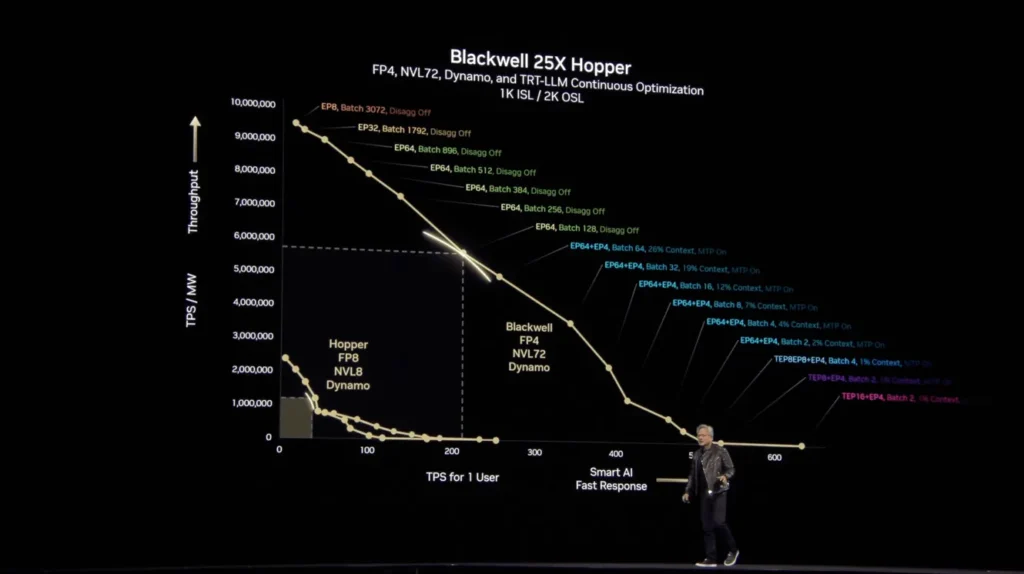
| Metric | GB200 NVL72 Performance Improvement | Reference System |
|---|---|---|
| LLM Inference | Up to 30X Faster | NVIDIA H100 Tensor Core GPU |
| LLM Training | Up to 4X Faster | NVIDIA H100 Tensor Core GPU |
| Energy Efficiency | 25X More Performance at Same Power | NVIDIA H100 Air-Cooled Infrastructure |
| Data Processing | 18X Faster | Traditional CPU Systems |
NVIDIA’s Full-Stack Dominance: CUDA, Dynamo, and the Ecosystem
NVIDIA’s commanding position in the AI domain extends far beyond its formidable hardware; it’s rooted in a comprehensive, full-stack approach. At the core of this ecosystem is CUDA, the foundational programming model that has cultivated a vast and indispensable library of accelerated computing frameworks and tools. This pervasive software layer is what truly unlocks the potential of NVIDIA’s GPUs. Complementing this is NVIDIA Dynamo, which Huang aptly describes as the “operating system of an AI factory.” Dynamo is designed to intelligently manage and optimize the incredibly complex inference workloads inherent in modern AI. It dynamically handles the distinct computational phases, such as pre-fill (context processing) and decode (token generation), and orchestrates various parallelism techniques—pipeline, tensor, and expert parallelism—alongside in-flight batching to maximize both efficiency and throughput across massive GPU clusters. This integrated software-hardware synergy, supported by critical partners like Synopsys leveraging CUDA-X libraries for chip design acceleration and major cloud providers deploying NVIDIA’s full stack, solidifies NVIDIA’s end-to-end dominance.
Jensen Huang succinctly captured the essence of Dynamo’s role:
“NVIDIA Dynamo does all that. It is essentially the operating system of an AI factory.”He further revealed its accessibility, stating, “It’s open source.” This strategic move underscores the critical importance of sophisticated software in orchestrating the intricate dance of AI workloads, ensuring NVIDIA’s hardware operates at peak efficiency within these burgeoning AI factories.

The Road Ahead: Blackwell Ultra, Rubin, and Beyond
NVIDIA’s roadmap reveals an aggressive, almost relentless pace of innovation, underscoring the long-term strategic planning required for AI infrastructure. For the second half of the current year, we anticipate Blackwell Ultra, an immediate upgrade to the platform, promising enhanced FLOPS, increased memory capacity, and greater networking bandwidth. Looking further ahead, the second half of next year will introduce the Vera Rubin platform, named after the pioneering astronomer. This will be a comprehensive generational leap, featuring an entirely new CPU and GPU architecture, alongside next-generation networking and the integration of HBM4 memory. The subsequent year, the second half of the following year, will see the arrival of Rubin Ultra, pushing the boundaries of extreme scale-up with NVLink 576, a staggering 15 exaflops of computational power, and a formidable 600kW per rack. This multi-year vista of innovation is crucial for hyperscalers and enterprises, allowing them to plan the land, power, and capital expenditure necessary to build these increasingly complex and powerful AI factories.



The Fandom Pulse: A Double-Edged Sword for Gamers?
While NVIDIA’s relentless pursuit of AI dominance elicits widespread awe and recognition for its technological prowess, particularly within the enthusiast community, it’s not without its undercurrents of concern. There’s a palpable sentiment, especially among consumers and smaller developers, that the sheer scale of this AI revolution is centralizing powerful technology within the grasp of hyperscalers and large enterprises. The focus on “AI factories” and multi-billion-dollar infrastructure raises questions about whether consumer-level innovation is being sidelined, or if high-end AI capabilities—such as efficient local inference for advanced models—will remain largely inaccessible to the average user. This concern extends to the gaming sphere, where users, while appreciating the trickle-down of technologies like DLSS, wonder about the direct availability of powerful, affordable AI hardware for personal projects or more sophisticated in-game AI beyond what current consumer GPUs offer.
“Still no cheaper consumer pci cards for inferencing workloads?”
This question encapsulates the growing frustration among consumers who, despite witnessing NVIDIA’s monumental AI achievements, yearn for more accessible and affordable hardware to leverage these capabilities personally.
The Gaming Connection: What NVIDIA’s AI Future Means for Us
For the LoadSyn audience, the immediate question often revolves around the direct impact of these enterprise-grade AI advancements on gaming. While the massive “AI factories” might seem distant, the reality is that the innovations forged at this extreme scale are fundamentally beneficial to the entire GPU ecosystem, including consumer gaming hardware. Technologies refined for efficiency and performance in Blackwell and Rubin, such as advanced Tensor Cores, new precision formats like NVFP4 optimized for inference, and sophisticated architectural improvements, are the very building blocks that will eventually trickle down to GeForce GPUs. This trickle-down effect directly enhances AI-powered gaming features like NVIDIA’s industry-leading DLSS (Deep Learning Super Sampling) for superior image quality and performance, as well as frame generation technologies that deliver smoother gameplay. Even if direct consumer-focused AI factory hardware isn’t the immediate priority, the underlying research and development in accelerated computing universally advances GPU capabilities, promising richer, more immersive gaming experiences and a new generation of AI-powered features within our favorite titles.
Pros: NVIDIA’s AI Dominance
- Unprecedented performance gains, with up to 30x faster inference and 4x faster training compared to H100.
- Industry-leading energy efficiency, delivering 25x more performance per watt at ISO power, crucial for power-limited data centers.
- A comprehensive full-stack ecosystem, from foundational CUDA and its vast libraries to the intelligent NVIDIA Dynamo operating system for AI factories, backed by strong partnerships.
- An aggressive and transparent roadmap (Blackwell Ultra, Rubin) that ensures sustained leadership and allows for multi-year infrastructure planning.
- Provides the foundational technology for the next era of computing, encompassing agentic AI, physical AI, and advanced scientific simulation.
Cons: Consumer/Gaming Implications
- The primary focus on hyperscalers and enterprise solutions may lead to slower or less direct consumer-specific innovation in dedicated AI hardware.
- High cost and limited direct accessibility of cutting-edge AI hardware for general consumers and smaller developers, fostering a sense of exclusion.
- Concerns about ecosystem centralization and heavy reliance on proprietary technologies like CUDA, potentially limiting alternative solutions.
- While trickle-down benefits to gaming are significant (DLSS, frame generation), the pace and directness of these advantages might not meet all consumer expectations for local AI workloads.
NVIDIA, under Jensen Huang’s visionary leadership, is undeniably the driving force behind the current AI revolution. Their “AI factory” blueprint, powered by the Blackwell and Hopper architectures, is transforming computing at an unprecedented scale, pushing the boundaries of what’s possible in generative AI, reasoning, and robotics. The sheer performance, efficiency, and integrated software stack they offer are unparalleled. However, the immense power and centralization of this technology present a critical challenge: balancing this enterprise dominance with broader accessibility and fostering innovation that benefits the entire ecosystem, especially the dynamic gaming community. As Dr. Elias Vance and LoadSyn, we will continue to meticulously dissect these developments, ensuring our readers understand both the profound technological leaps and the evolving implications for all users, from hyperscalers to the everyday gamer. The future of AI is being built now, and its accessibility will define its ultimate impact.
Frequently Asked Questions
What is an ‘AI Factory’?
An ‘AI Factory’ is Jensen Huang’s term for advanced data centers specialized in generating ‘tokens’ (the building blocks of AI models) at massive scale, using high-performance GPUs like NVIDIA’s Blackwell and Hopper. They are designed for training and deploying trillion-parameter AI models with extreme efficiency, marking a shift from traditional retrieval-based computing to generative computing.
How much faster is Blackwell than Hopper for AI?
NVIDIA’s Blackwell architecture offers significant performance improvements over Hopper. For real-time large language model (LLM) inference, the GB200 NVL72 system is up to 30x faster than previous Hopper H100 systems. For LLM training, it’s about 4x faster. More broadly, Blackwell delivers 25x more performance at the same power (ISO power) compared to H100, especially for reasoning models, while also showing a 40x increase for reasoning models specifically.
What is NVIDIA Dynamo?
NVIDIA Dynamo is described by Jensen Huang as the ‘operating system of an AI factory.’ It’s a complex, open-source software system designed to manage and optimize diverse inference workloads across large GPU clusters. It intelligently disaggregates and distributes tasks like pre-fill (context processing) and decode (token generation), and employs pipeline, tensor, and expert parallelism with in-flight batching to maximize efficiency and throughput, adapting to varying computational demands.
Will these new AI GPUs impact consumer gaming hardware?
Absolutely. While the direct ‘AI factory’ hardware is for hyperscalers and large enterprises, the technological innovations developed for these high-end AI GPUs will inevitably trickle down. This includes advanced Tensor Cores, new precision formats like NVFP4, improved energy efficiency, and software optimizations. These advancements will enhance AI-powered gaming features such as DLSS (Deep Learning Super Sampling), frame generation, and potentially lead to more sophisticated in-game AI, driving the next generation of graphics fidelity and performance in consumer GPUs.
Is NVIDIA’s AI dominance a concern for the broader market?
While NVIDIA’s technological leadership is widely recognized, the community and industry observers express concerns about market centralization. The heavy reliance on proprietary ecosystems like CUDA and the high cost/limited accessibility of cutting-edge AI hardware for smaller entities raise questions about competition and the pace of innovation outside NVIDIA’s direct control. This tension is a significant discussion point for the future of AI and GPU development, particularly regarding broader market accessibility.







